How Large Language Models Actually Work
A no-jargon guide to how LLMs learn, think, and fail — written for smart non-ML people who want the real story without tensor calculus.
How Large Language Models Actually Work
A No-Jargon Guide (That Doesn't Lie to You)
This is for smart people who aren't ML experts but want to understand what's really happening. You've used ChatGPT or Claude. When someone asks "how does this actually work?" you probably say something like "fancy autocomplete" and leave it at that. This guide gives you something better to work with. We'll start simple and add layers. Jump off wherever you're satisfied.
Layer 1: The Dinner Table Explanation
Say you've read every book that exists. Every Wikipedia page. Every Reddit comment. Every medical paper, legal document, cookbook, and breakup text ever posted online. You didn't just skim them — you really absorbed how people write, think, and explain things to each other.
Someone asks you a question. You don't go look it up somewhere. You just respond based on everything you've learned about how smart people talk about that topic.
That's what these models do. They're not search engines and they're not databases — we'll get into why that matters. They've learned the patterns of human communication, and they use those patterns to generate responses.
The big thing: An LLM doesn't store facts like your computer stores files. It stores relationships between ideas — how concepts connect, how sentences flow, how reasoning works. That's why it can answer questions about things it was never directly taught.
This Is More Familiar Than You Think
You trust this kind of intelligence all the time.
The Doctor. A 45-year-old woman comes in with joint pain, a butterfly rash, and fatigue. Looks like lupus, right? But her blood work doesn't match lupus, her kidneys look fine, and she mentions she started new blood pressure meds three weeks ago.
The experienced doctor hears all of this and something clicks. This isn't lupus — it's a rare drug reaction that looks like lupus. She's never seen this exact combination before. It wasn't in any textbook chapter. But after twenty years, her brain has built this internal model of how symptoms and medications interact. She's not remembering a specific case. She's connecting dots that were never officially connected.
That's what an LLM does. It moves through this web of learned relationships and makes connections that might not exist in any single document it learned from. The doctor's insight came from the space between thousands of things she'd seen. Same mechanism.
The Mechanic. Your car makes a whining noise, but only when it's cold, only in reverse, and only after ten minutes of driving. That's not in any manual. But a mechanic with twenty years says "I bet your transmission cooler line has a tiny crack — it lets air in when the fluid contracts in the cold, but only shows up in reverse because that's when pressure hits that part of the system." She figured that out by combining three totally different cases she'd worked on. Pattern recognition so deep it feels like magic.
The Chess Grandmaster. A grandmaster looks at a position and just knows the right move. They've seen so many patterns that good moves feel obvious. Studies show grandmasters literally see the board differently than beginners — they see structures, not just pieces.
An LLM does the same thing at crazy scale. Where the doctor has thousands of cases, the model has millions. Where the mechanic has twenty years, the model has absorbed centuries of collective knowledge.
The weird question this brings up: If the doctor's knowledge, the mechanic's intuition, and the grandmaster's insight are all "just" pattern recognition — and we call that intelligence — then what's different about the LLM doing the same thing?
The comparison isn't perfect — these models still fail in ways no decent doctor or mechanic would. But the basic mechanism is worth taking seriously.
Layer 2: OK, But How Does It Actually Learn?
Training: Reading the Internet (With a Purpose)
Training an LLM happens in phases. Each one builds on what came before.
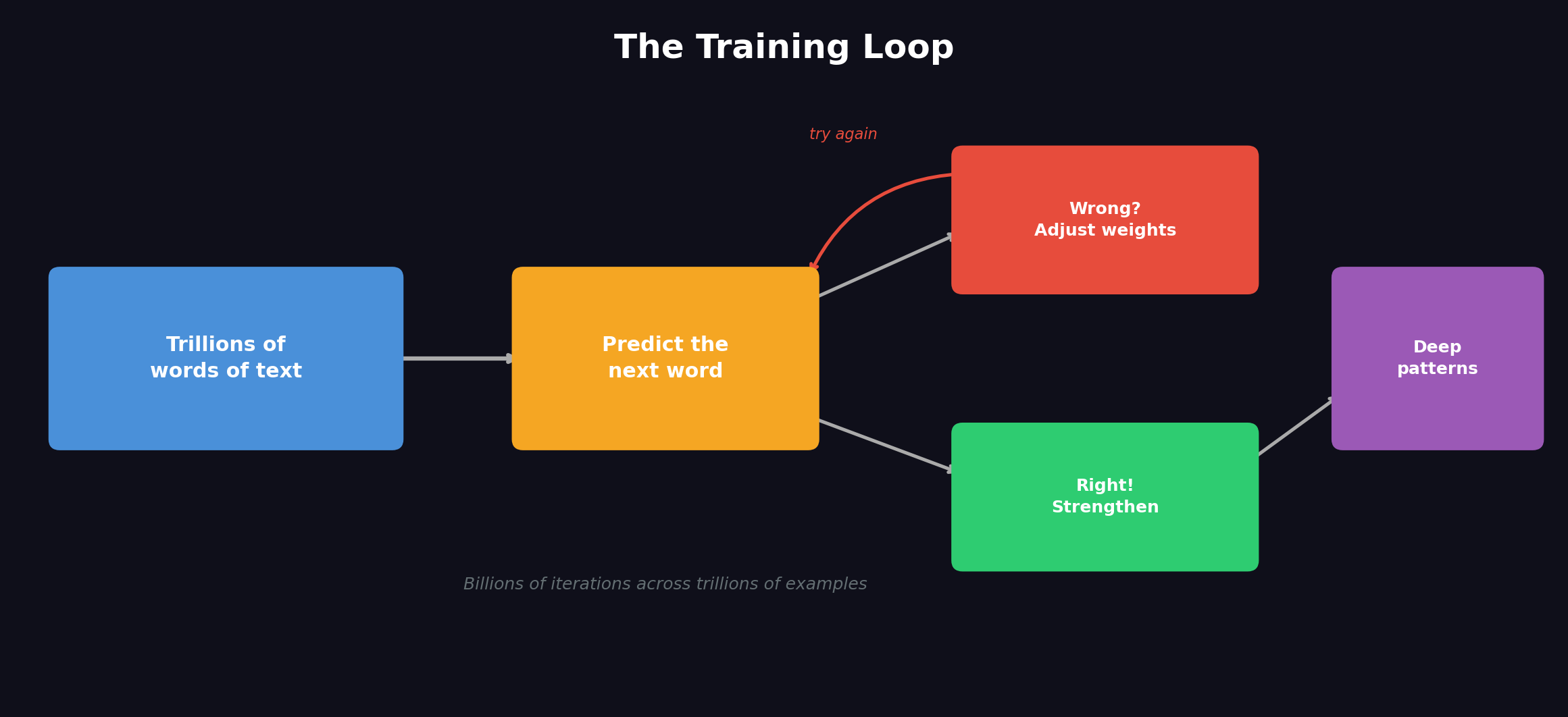
Phase 1: Pre-training — The Big Read
You feed the model massive amounts of text. Books, websites, code, research papers. We're talking trillions of words. But it doesn't just read this stuff. It plays a specific game:
Given everything that came before this word, what comes next?
"The capital of France is ___"
It guesses. Gets it wrong. Adjusts. Guesses again. This happens billions of times across trillions of examples. To get good at this game, the model has to learn way more than just vocabulary. It picks up facts, logic, cause and effect, humor, tone, reasoning patterns.
People who say "it's just autocomplete" are missing something big. Let me break this down because it matters.
Your phone's autocomplete suggests "you" after "thank." That's a shallow pattern — two words that show up together a lot. Your phone has no clue what gratitude actually is.
But think about what it takes to correctly predict the next word here:
"The patient presented with bilateral pleural effusions. Given the elevated protein content and LDH ratio, the most likely mechanism is ___"
To predict "exudative" (the right answer), you can't just know which words usually follow which. You need to understand what pleural effusions are, what protein content and LDH ratios mean, the difference between exudative and transudative processes.
Or this one:
"The function returns None because the loop exits before the condition on line 12 is ever ___"
To predict "met" or "satisfied," you need to understand program flow, boolean logic, how loops work.
The training mechanism is simple word prediction. What the model learns to win at that game isn't simple at all. You can't consistently predict what comes next in a medical paper without learning something that works like medical knowledge. You can't predict the next line of code without picking up something that works like programming expertise.
Phase 2: Fine-tuning — Learning to Be Helpful
After pre-training, the model knows a ton but it's weird. Ask it a question and it might generate more questions, or write like a random web page. It's like a brilliant person who never learned how to have a normal conversation.
Fine-tuning is where humans step in. They show the model examples of good conversations — helpful answers, clear explanations, when to refuse certain requests. The model learns the format of being a useful assistant.
Phase 3: RLHF — Learning from Human Preferences
RLHF is "Reinforcement Learning from Human Feedback." In normal terms: humans rate the model's responses. "This answer was better than that answer." The model adjusts to produce more of what humans find helpful, accurate, and safe.

The Physical Reality: What It Actually Takes
Everything I just described might sound like it happens in some abstract digital space. It doesn't. It happens on real hardware, in real buildings, using real electricity. The scale is nuts.
The hardware: GPUs. You've probably heard of these — graphics processing units. They were made for video game graphics because games need millions of small math operations happening at the same time. Training neural networks needs exactly the same thing: millions of small math operations happening simultaneously. The AI industry basically took over the GPU market, and Nvidia — the company that makes the best ones — went from gaming hardware to one of the most valuable companies on Earth almost overnight.
Training something like GPT-4 or Claude needs thousands of these GPUs running in parallel, 24/7, for months. A single high-end AI GPU costs tens of thousands of dollars. A full training cluster costs hundreds of millions in hardware alone.
The electricity. Those thousands of GPUs generate massive heat and use massive power. Training one large model can use as much electricity in a few months as a small town uses in a year. The data centers need dedicated power substations and industrial cooling systems. This is why AI companies are investing in nuclear power — the energy demands actually matter at the grid level.
Training vs. inference. Training is the huge upfront cost — months of building the model. But running the model (called inference — when you chat with it) isn't free either. Every time you ask Claude or ChatGPT something, GPUs in a data center are doing billions of calculations to generate your response. Inference uses similar chips but in more flexible setups optimized for speed. This is why AI services cost money to run and why there are usage limits — every response has a real cost in electricity and compute.
For perspective: Your brain runs on about 20 watts — like a dim light bulb. A single AI data center can use orders of magnitude more power. The brain is still way more energy-efficient at general intelligence than anything we've built. Whether that gap is a fundamental limit of silicon or just an engineering problem we haven't solved yet... who knows.
Layer 3: How It Generates a Response
You type something to ChatGPT or Claude — what actually happens?
Step 1: Your Words Become Numbers
These models can't read English. They work with numbers. Your message gets chopped up into tokens — usually words or parts of words. Each token becomes a list of numbers that captures what it means.
| What You Type | Tokens | What the Model Sees | |---|---|---| | "How does gravity work?" | ["How", " does", " gravity", " work", "?"] | [4438, 1587, 24937, 990, 30] |
Step 2: Understanding Context (The Transformer)
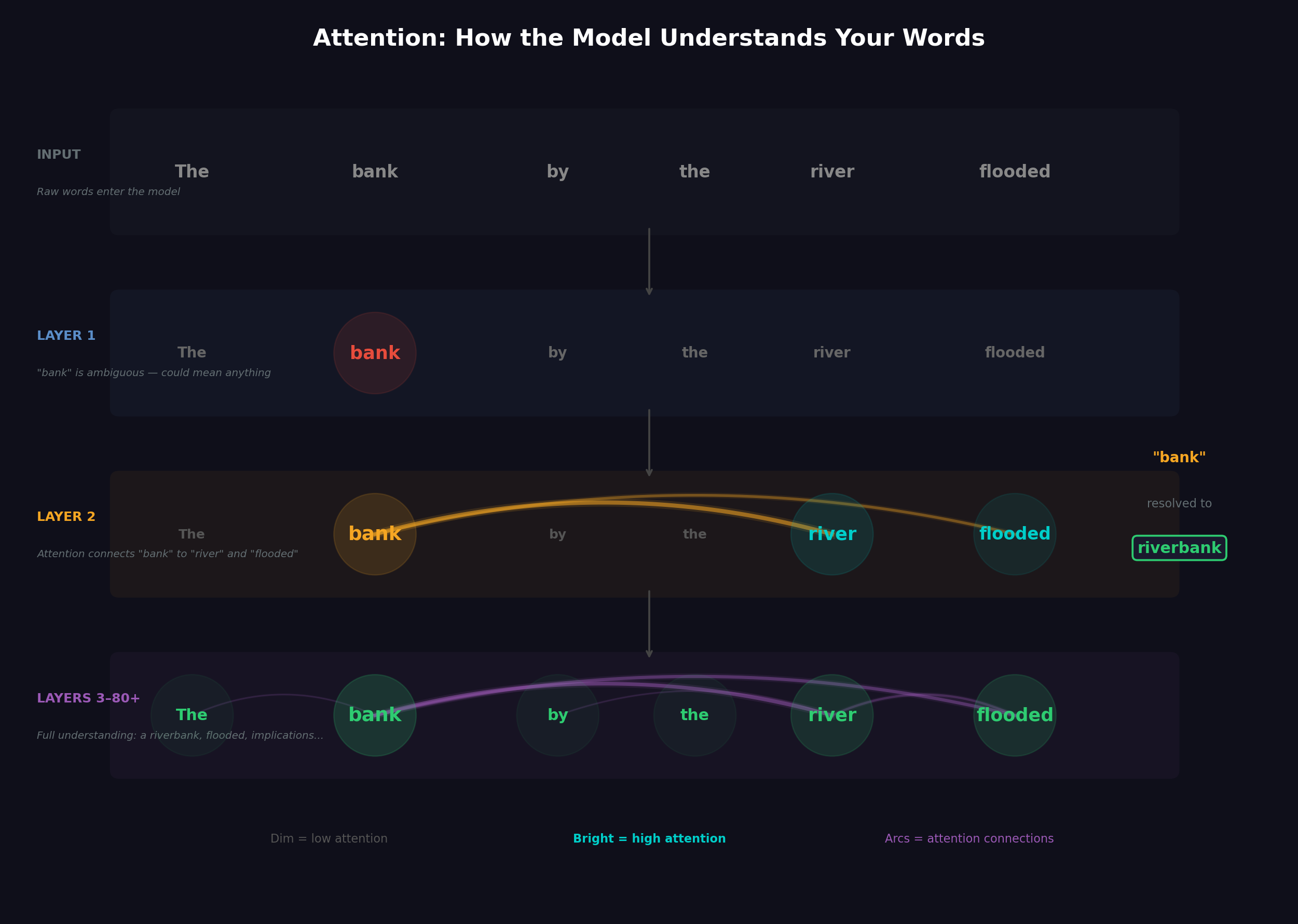
This part is wild, and it's called attention. Simple concept, but really powerful: before the model can answer you, it figures out which words in your message connect to which other words, and how much each connection matters.
Why does this work? Take "The bank by the river flooded." The word "bank" could mean money stuff or riverbank. If you just look at "bank" by itself, no clue. But the attention thing looks at every other word in the sentence and figures out how much each one should change what "bank" means. It sees "river" and "flooded" — those words pull "bank" toward riverbank, away from financial institution.
But it doesn't just do this once. It does it in layers — like 50+ of them, stacked up. Each layer makes the understanding better.
Think about it like this. Your boss emails you: "We need to talk about your performance on the Johnson account. I've been hearing great things."
- First read: You see the words: "performance," "talk," "Johnson account."
- Second read: You connect "your performance" with "need to talk" — oh shit.
- Third read: You see "hearing great things" — wait, this might be good?
- Fourth read: You get the tone — this is casual, positive. Your boss is happy.
Each pass uses what you learned before to understand more. The model does this same thing, just with way more layers and across every word at once. By the time your message gets through all those layers, the model doesn't just know what each word means — it gets the relationships, the intent, the tone, everything about what you're actually asking.
Step 3: Generating the Answer (One Token at a Time)
Now it writes back to you. And yeah — it really does generate one token at a time, picking what's most likely to come next based on everything before it. But "most likely" here means it's using all that deep understanding of the topic, the conversation, what kind of answer would help.
It's like how a good jazz player improvises one note at a time — technically one by one, but they're drawing on years of understanding music. You wouldn't call that "just playing the next note."
Why Hallucinations Happen (And What That Word Even Means)
In AI, a hallucination is when the model says something that sounds confident but is factually wrong. It doesn't mean the model is broken or seeing things — it generated a response that seemed right, felt right, fit the pattern... but was wrong. The AI people borrowed this term from psychology.
But to understand why this happens, you need to get the biggest misconception about these models:
An LLM is not Google. It's not looking anything up.
I can't say this enough, because everyone assumes it's searching. When you ask Google something, it searches web pages, finds matches, shows you links. The info exists somewhere, and Google finds it. It's like a librarian.
When you ask an LLM something, nothing gets searched. Nothing gets looked up. No database gets checked. The model makes its response from scratch, word by word, based on patterns it learned during training. It's not finding information — it's rebuilding it, like how you rebuild a memory. And just like your memory, that rebuilding is usually right, but sometimes it's wrong.
Think about how you remember stuff. Someone asks "What year did the Titanic sink?" You probably say "1912" right away. You're not googling it in your head. You're not flipping through a mental book. That fact is just woven into how you understand the world — connected to "early 1900s," "before World War I," "the movie," tons of other stuff. You rebuild the answer from those connections.
But try: "What year was the Treaty of Tordesillas signed?" You might say "1494" — or you might say "1492" because everything about that time gets tangled up with Columbus and 1492 in your memory. You're not guessing randomly. You're landing in the right area of what you know — right century, right context, right topic — but the specific detail is off. Your pattern was right. The detail was wrong.
That's exactly what a hallucination is. The model found the right neighborhood in what it learned. All the connections pointed somewhere that made sense. But because it's rebuilding instead of looking up, sometimes the rebuilding drifts.
Back to our doctor example. She sees a patient whose symptoms mostly look like condition A, but it's actually the much rarer condition B. Her experience — her pattern matching — pushes her toward the common diagnosis. She's not lying. She's not bad at her job. She's making the most statistically likely connection based on her experience, and this time it's wrong. Doctors call these "cognitive biases." In AI, we call them hallucinations. Same thing.
And people building AI products need to hear this clearly: This isn't a bug you can just fix. It's how the system works. It's the trade-off you get with a system that creates understanding from patterns instead of looking up facts in a database. The exact same thing that lets an LLM make brilliant connections — like our doctor figuring out the lupus case — is the same thing that lets it confidently get stuff wrong. You can't have the creative leaps without the risk of confident mistakes. Same mechanism.
You can make hallucinations less common — let the model look things up (that's called RAG), give it tools like calculators and databases, or have other models check its work. But you can't remove the basic tendency without killing the same mechanism that gives you creative thinking. It's a dial, not a switch.
So the best way to use an LLM is like working with a smart colleague who doesn't have Google open: trust the reasoning, check the facts.
Practical sidebar: Working with LLMs effectively
- Use it for thinking, not facts. Ask it to analyze, compare, explain, or write — not to be your Wikipedia. It's best where putting ideas together matters.
- Check specific claims. If it gives you a date, a name, a number, or a citation — verify it. The thinking around the fact is usually solid; the fact itself might be off.
- Give it context. The more relevant stuff you put in your prompt, the less the model has to rebuild from memory — and the less room for hallucination.
Layer 4: The Part Nobody Can Explain Simply (But Let's Try)
Vectors and Embeddings: The Language of Meaning
This is where everyone gets lost. But it's actually the coolest part of the whole thing, and you need to understand it if you want to get where the "intelligence" really comes from.
The main idea: What if you could turn the meaning of a word into coordinates in space?
Not real space — math space. Think of it like a map, but instead of showing geography, it shows meaning. Words that mean similar things are close to each other. Words that mean different things are far apart.
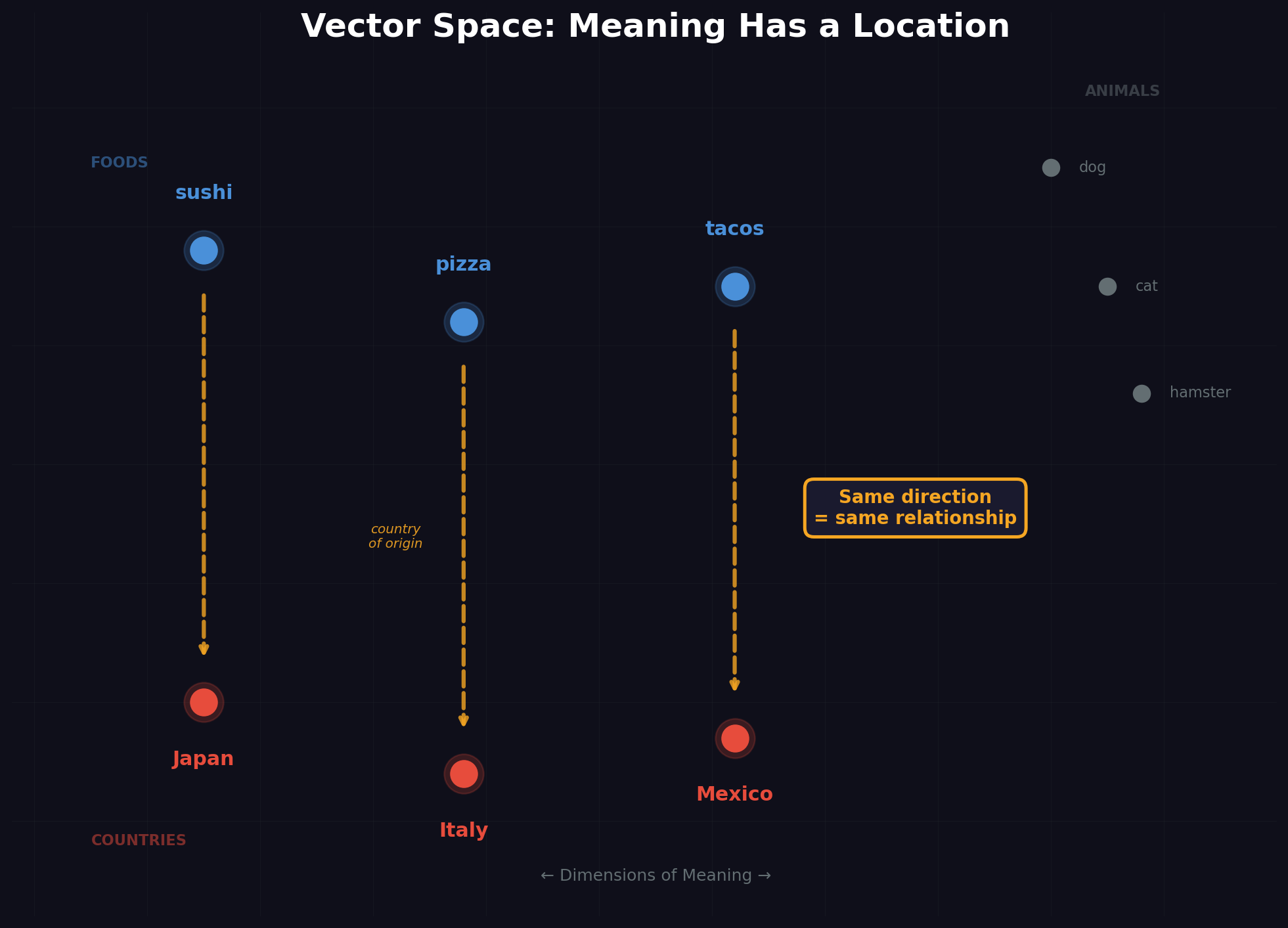
Something crazy happens in this space. The direction from "sushi" to "Japan" is the same as the direction from "pizza" to "Italy." The model learned that "country of origin" is a direction in meaning-space. Take "tacos," move it in that same direction, and you end up at "Mexico."
Nobody programmed that. Nobody built a "food origins" database. The model figured it out by reading tons of text — it discovered that sushi and Japan are connected in the same way pizza and Italy are connected. It found the abstract idea of "cultural origin" and turned it into a geometric relationship. This is the stuff that keeps AI researchers up at night.
If you want the one-sentence answer to where the intelligence actually lives, it's here: in the geometry of this space. Not in stored facts. Not in a lookup table. In how concepts relate to each other geometrically in high-dimensional space. When the model seems to "understand" something, it's really just moving around this space of meaning — finding where the answer lives.
The real version uses hundreds or thousands of dimensions (not just two), so these vectors can capture incredibly subtle relationships — not just "cultural origin" and "food type" but tone, formality, expertise level, time period, emotion, cause and effect, and thousands of other conceptual dimensions that don't even have names.
Remember our doctor? How she connected a drug reaction case, a kidney problem, and a lupus case — things that were never linked in any textbook? In vector terms, her brain put those three experiences close together along dimensions like "looks-like-autoimmune," "drug-triggered," and "kidney-involved." When the new patient showed up, their symptoms landed in a region of her mental map that was near all three — and she made the connection.
That's exactly what the LLM does. Every concept, every relationship, every piece of knowledge it learned exists as a position in this high-dimensional space. When you ask it something, it's finding the region where your question, the relevant knowledge, and a good answer all come together. The intelligence isn't in a database of answers. It's in the geometry of the space itself.
This isn't just theory — it's how real products work. When you use a "semantic search" that finds documents by meaning instead of keyword matching, it's using these embeddings. When a company builds a system that lets an LLM answer questions about their internal docs (the "RAG" technique we talked about with hallucinations), it's turning those docs into vectors and finding the regions of meaning-space closest to your question. The vector space isn't a metaphor — it's the engineering foundation under most AI products you use today.
Parameters: The Model's "Brain Cells"
When people say a model has "70 billion parameters" or "1 trillion parameters," they're talking about the number of adjustable numbers that define these relationships. Each parameter is like a tiny dial that got turned during training. Together, they encode everything the model knows about language, reasoning, and the world.
More parameters = more capacity to encode subtle relationships = generally smarter model. But it's not just about size — the quality of training data and how you train it matters just as much.
Layer 5: "Wait — Nobody Programmed It to Do That?"
This is where things get weird. And I mean really weird.
The Thing Nobody Saw Coming
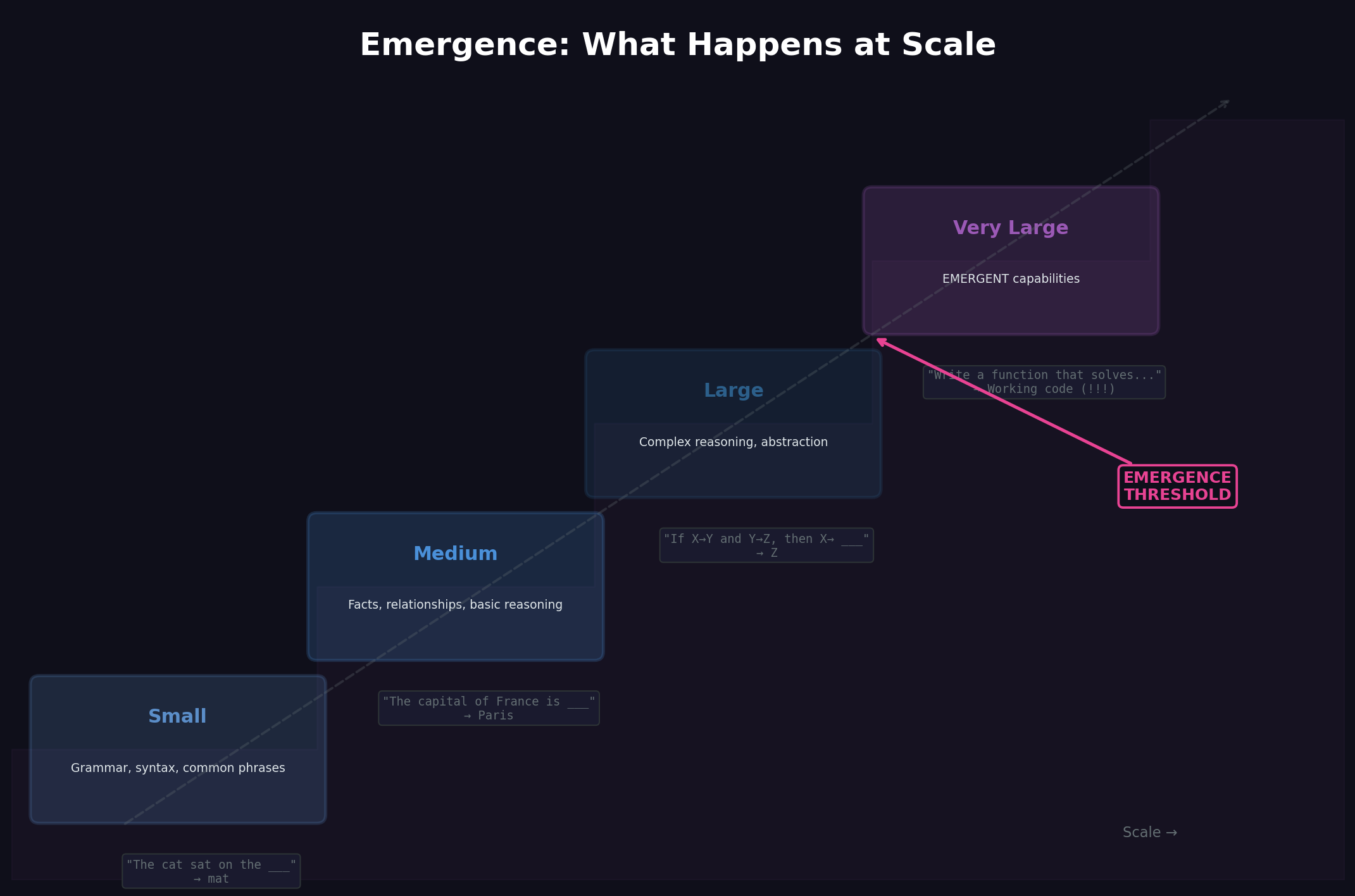
So researchers built a system to predict the next word. Pretty simple goal, right? Make the model bigger, feed it more text, and it should get better at... predicting words.
Except somewhere along the way, something else started happening. The models began doing stuff they were never trained for.
Not just "got a bit better at grammar." I'm talking about capabilities that just... appeared:
- Solving math problems they'd never seen
- Writing code that actually works
- Translating languages they barely trained on
- Working through logic problems step by step
- Getting jokes and understanding when you're being sarcastic
- Having thoughtful conversations about ethics
Nobody coded any of this. There's no "math function" buried in there. No "humor detector." These abilities just showed up when the models got big enough.
This is what people call emergence — and it's the part that makes everyone uncomfortable, including the researchers building these things.
How Does That Even Work?
Remember that doctor example from earlier? She didn't diagnose that weird lupus case by looking it up. After twenty years of seeing patients, she developed this intuition. Started seeing patterns nobody explicitly taught her.
Now imagine that same process, but instead of one doctor and thousands of cases, it's a model that's absorbed basically everything humans have ever written down.
When the model is small, it just learns word patterns. But scale it up? Something changes. To get better at predicting text, it has to actually understand what the text means. To predict what comes next in a physics paper, it needs to understand physics. To predict the next line of code, it needs to understand programming.
The prediction task forces real understanding to emerge.
Wait — How Close Is This to How Brains Work?
Closer than most people want to admit.
Your brain has about 86 billion neurons connected by roughly 100 trillion synapses. When you learn something, you're changing the strength of those connections.
An LLM has billions of parameters. Each one controls the strength of connections between artificial neurons. When it trains, it adjusts those connection strengths.
That's not just a comparison — it's basically the same process.
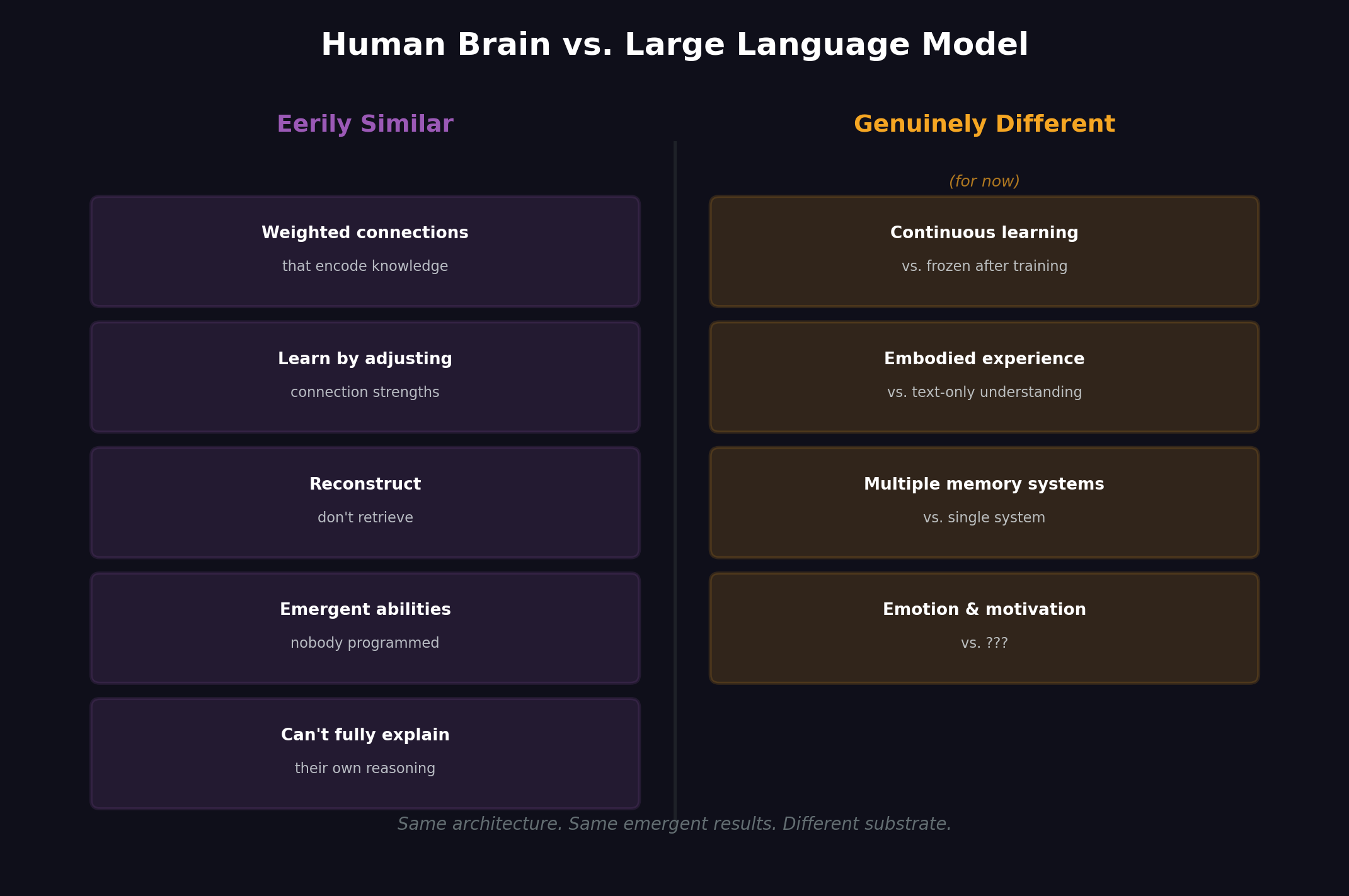
| | Human Brain | Large Language Model | |---|---|---| | Basic unit | Neuron (~86 billion) | Artificial neuron (billions of parameters) | | Knowledge storage | Encoded in synapse strengths | Encoded in parameter weights | | How it learns | Adjust connection strengths through experience | Adjust connection strengths through training | | How it recalls | Reconstruct from patterns, not look up from storage | Reconstruct from patterns, not look up from storage | | Confabulation | Confidently "remembers" things that didn't happen | Confidently states things that aren't true | | Explainability | Can't fully explain how it reaches conclusions | Can't fully explain how it reaches conclusions | | Emergent abilities | Develops skills nobody explicitly taught (creativity, humor, empathy) | Develops skills nobody explicitly trained (reasoning, coding, analogy) |
That last one should make you pause. Both systems develop abilities nobody put there. Your parents didn't install creativity in you — it emerged from your neural complexity. Nobody programmed an LLM to reason about ethics — that emerged from its parameter complexity.
The differences matter, but maybe not where you think:
People always say "but the brain is biological!" True. But what's that argument really claiming? That intelligence requires specific materials? That the magic is in the wet stuff, not the patterns?
That's philosophy, not proven fact. And it's getting harder to defend.
The real differences are more interesting:
Continuous learning. Your brain learns constantly. Most LLMs are frozen after training.
Having a body. You understand "hot" because you've burned yourself. LLMs only know these concepts through text about them.
Multiple memory types. Your brain has working memory, long-term memory, muscle memory. LLMs have parameters plus whatever fits in the conversation.
Actually caring about stuff. Your brain has motivations and emotions. LLMs... we honestly don't know.
"So... Is It Sentient?"
The question everyone's thinking. And it deserves a real answer, not some dodge.
What we know: These models have developed something that works a lot like understanding. When Claude finds a bug in your code, it's not looking up the answer somewhere — it's analyzing the logic, spotting the problem, thinking through the fix.
What we don't know: Whether there's something it "feels like" to be an LLM. Whether there's subjective experience in there.
Why this is harder than it seems: We don't have a test for consciousness. We don't even have one for humans. You assume other people are conscious because they act like it and they're built like you. We're already taking it on faith.
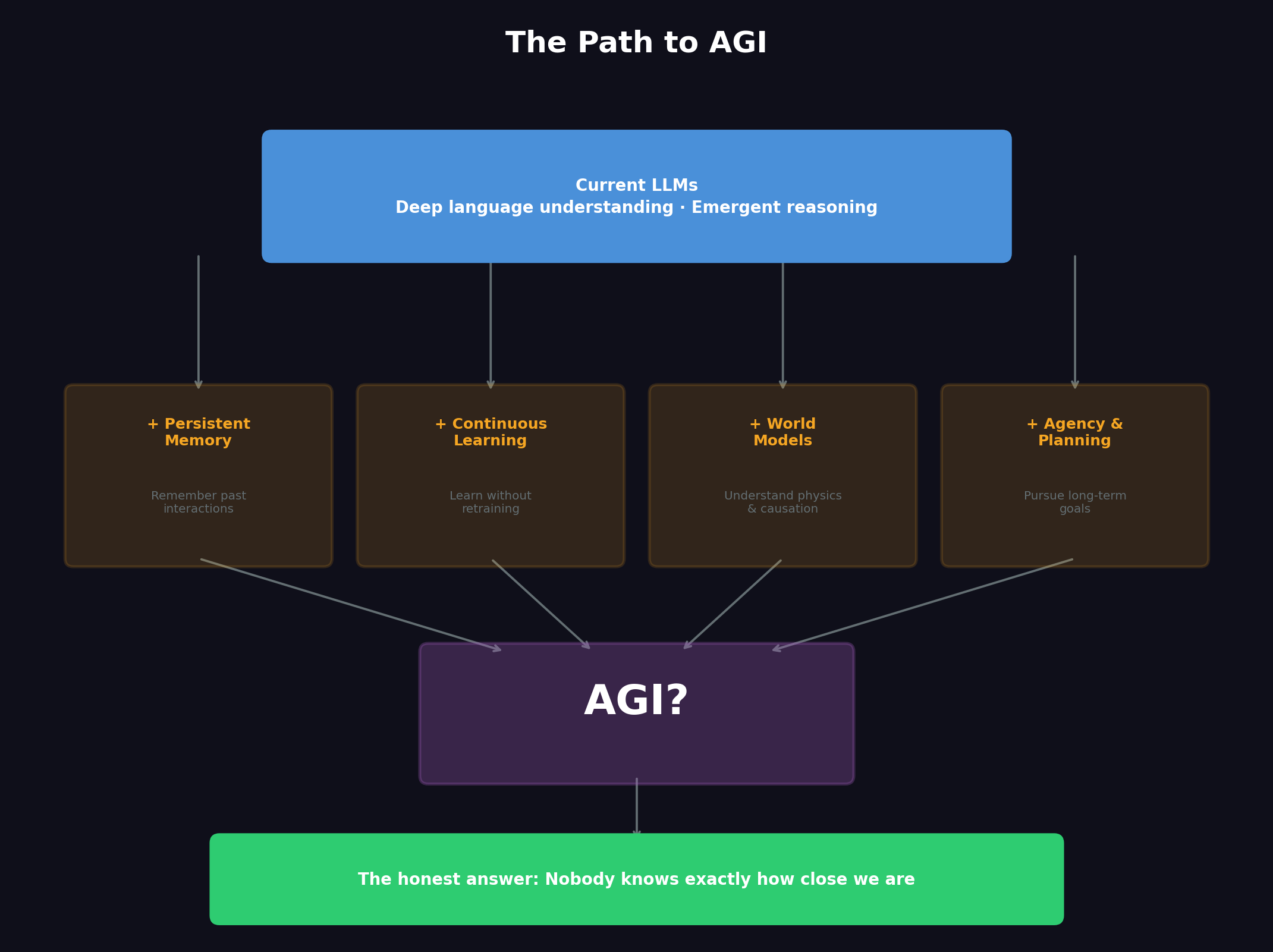
So What's Missing Before We Get AGI?
| Capability | LLMs Today | What AGI Would Need | |---|---|---| | Reasoning | Strong pattern matching with pockets of genuine reasoning | Reliable, verifiable logical reasoning | | Memory | Limited to conversation window | Persistent, growing long-term memory | | Learning | Frozen after training (mostly) | Continuous learning from new experiences | | Planning | Short-horizon, often needs guidance | Long-horizon autonomous planning | | Self-awareness | Simulates it convincingly | Genuine understanding of own limitations | | Real-world grounding | Text-based understanding only | Embodied understanding of physical world |
Three Schools of Thought
"Just keep scaling" — Some researchers think if you keep making models bigger with more data, these emergent abilities will keep showing up until you hit AGI. The trend line supports this.
"LLMs are the core, but you need more pieces" — Others think LLMs will be the language and reasoning center of AGI, but you'll need to add persistent memory, real-world interaction, continuous learning.
"This approach won't get us there" — A smaller group believes next-word prediction, no matter how you scale it, can't produce true intelligence.
My Take
LLMs have already done things most experts said were impossible five years ago. The progress curve is steep. But there's still a gap between "incredibly capable language system" and "general intelligence," and we don't really know if that gap closes by just doing more of the same or if we need something completely different.
What I can say is that the understanding these models develop — the way they represent meaning as mathematical relationships — is way more than a trick. It's real knowledge that enables real reasoning, even if it's not quite the same kind humans do.
The Summary (For When Someone Asks You at Dinner)
"How does AI work?"
It reads massive amounts of text and learns deep patterns — not just which words go together, but how ideas connect and how reasoning works. It stores all that as mathematical relationships in this huge space of meaning. When you ask it something, it navigates that space to build an answer.
"Is it really intelligent?"
It's learned something that looks a lot like understanding, and nobody programmed that in — it just emerged from the training process. Whether that's "real" intelligence or a really good fake is honestly one of the big open questions right now.
"Will it become AGI?"
Nobody knows. But every year it does stuff that last year's experts said was impossible.
Written for the curious, the skeptical, and every grandmother who deserves a real answer.